Sentiment analysis is a valuable tool for examining the emotional tone and bias in text data. While it is commonly used in marketing and customer service, I’m particularly interested in its application for fake news detection.
Fake news often employs sensationalist or emotionally charged language to manipulate readers. By identifying these sentiment patterns, sentiment analysis can flag potentially misleading content and reveal coordinated disinformation campaigns. This makes it a critical component in the broader strategy to combat fake news and misinformation.
In this post, I’ll describe the training of a sentiment analysis model using the Hugging Face ecosystem. My project utilizes the BERT architecture, fine-tuned on the IMDb and GLUE SST2 datasets, leveraging Hugging Face’s tools for efficient training, fine-tuning, and deployment of machine learning models.
I’ll discuss the model’s enhancement process, evaluate its performance, and compare it with other leading models. Additionally, a live demo hosted on Hugging Face Spaces will showcase the model’s real-time analysis capabilities.
Let’s explore the practical application and advantages of using the Hugging Face ecosystem for advanced NLP tasks.
Table of contents
- Hugging Face
- Building The Model
- Fine-tuning The Model
- Model Training with Hugging Face Trainer API
- Model Deployment on Hugging Face Model Hub and Spaces
- Performance Benchmarks
- Conclusion
Hugging Face
I chose to implement this project with Hugging face transformers library, because Hugging face libraries are really well documented, giving all needed information in one place. Its whole ecosystem was guiding me from learning to training my first model and deploying it in real application by hosting it on their own Hugging Face spaces. And that all for free!
The Hugging Face Model Hub offers access to hundreds of thousands of pre-trained models. Leveraging a pre-trained model for tasks like sentiment analysis reduces training time and the computational resources required. It also minimizes the amount of training data needed, as these models are already proficient in language understanding. By using a pre-trained model, you can tap into state-of-the-art performance from base models trained on specific task.
To get a basic understanding of the transformer models I recommed to take this Hugging Face NLP course. It was a great starting point for me, guiding me to peek under the hood of the transformers architecture, using the models, fine-tuning them and share them back to the Hugging Face community.
Building the model
To create model for sentiment analysis I needed basically two things:
- Model with contextual understanding - This means the model considers the full context of a word by looking at the words that come before and after it, which is crucial for understanding sentiments that can be heavily context-dependent.
- Dataset to finetune the model For the specific task of sentiment analysis, I need dataset consisting of text with sentiment label (positive, negative, neutral, happy etc.)
The transformers model - BERT
The BERT (Bidirectional Encoder Representations from Transformers) model was an ideal choice for this project due to several of its features. BERT’s architecture enables it to understand the context from both the left and the right side of a word within a sentence. This bidirectionality is particularly advantageous for sentiment analysis, where the sentiment expressed can depend greatly on the context provided by surrounding words.
BERT also comes pre-trained on a massive corpus, including the entire English Wikipedia and the BookCorpus dataset, encompassing over 2.5 billion words. This extensive pre-training allows BERT to have a nuanced understanding of language, which is crucial for handling the complexities of human emotions expressed through text.
DistilBERT: A Leaner, Faster Alternative to the Bulky BERT
DistilBERT is a smaller, faster, and lighter version of BERT. Developed by Hugging Face, DistilBERT aims to deliver much of the same performance as BERT but with fewer resources and faster processing times. It is created through a process known as knowledge distillation, where a smaller model (the “student”) is trained to reproduce the behavior of a larger model (the “teacher”)—in this case, BERT.
Despite its reduced size, DistilBERT retains up to 97% of BERT’s performance on several key NLP benchmarks. This makes it highly effective, particularly in scenarios where a slight trade-off in accuracy is acceptable for gains in efficiency.
Fine-tuning The Model
Fine-tuning a pre-trained model like BERT or DistilBERT on a specific task is a common strategy in natural language processing to adapt the broad capabilities of a general model to a more focused application.
The choice of training data on which to fine-tune the model depends on the purpose of the model. The training data should be close to the expected live data but not too much close to let the model generalize good on the unseen data. The generalization - specialization needs to be balanced based on the purpose of our model.
For fine-tuning I chose pre-trained DistilBERT model for the reason of faster fine-tuning time compared to basic BERT model. I ran the model fine-tuning in Google colab (free version), where BERT’s traning on T4 GPU takes nearly 3 hours, while DistilBERT requires only 1 hour of training.
The aim of this model is to recognize usual sentiment in the sentences, therefore I used the IMDb movie dataset and GLUE SST2 dataset, which offers big variance in the data.
The IMDb dataset
The IMDb dataset consists of 50,000 movie reviews, balanced between positive and negative sentiments. Each of these reviews is labeled. Each item of the dataset consists of two columns ‘text’ and ‘label’. The text is not preprocessed any way, the label is an integer value of either 0 or 1, where 0 is a negative review, and 1 is a positive review.
| text | label |
|---|---|
| I rented I AM CURIOUS-YELLOW from my video store because of all the controversy that surrounded it when it was first released in 1967. I also heard that at first it was seized by U.S. customs… | 0 |
| I can’t remember many films where a bumbling idiot of a hero was so funny throughout. Leslie Cheung is such the antithesis of a hero that he’s too dense to be seduced by a gorgeous vampire… I had the good luck to see it on a big screen, and to find a video to watch again and again. 9/10 | 1 |
The GLUE SST2 dataset
To improve the model I wanted to add more variety to the training data and that’s why I chose GLUE SST2 dataset. GLUE is defacto standard for general language understanding evaluation, even so at this moment already deprecated (check Super-Glue).
Model Training with Hugging Face Trainer API
To see the model training in action checkout my Google Colab Notebook. For the details of the model training check below.
To fine-tune the BERT model for sentiment analysis, I used the Hugging Face Trainer API. The Trainer API simplifies the training and evaluation process while providing a lot of flexibility. Here’s a summary of the steps involved:
Dataset Preparation
I imported the IMDb dataset through the datasets library provided by Hugging Face. This dataset comes pre-processed, simplifying the task of getting the data into a suitable format.
The IMDb dataset consists of two subsets ‘train’ and ‘test’. Each subset has 25 000 examples, which doesn’t follow the best practices to split the data for the model training. Therefore I merged the subsets and splited the whole dataset into 60-20-20 (train-validate-test) hoping for better results.
def load_and_split_dataset(dataset_name):
# Split ratios
train_split = 0.6
test_split = 0.2
# Load the dataset
dataset_train = load_dataset(dataset_name, split="train")
dataset_test = load_dataset(dataset_name, split="test")
# Merge them and shuffle
dataset_full = concatenate_datasets([dataset_train, dataset_test])
# Shuffle the data with fixed seed to ensure the reproducibility of the dataset
dataset_full = dataset_full.shuffle(seed=42).flatten_indices()
# Calculate the number of samples for train, validate, and test
total_samples = len(dataset_full)
train_size = int(total_samples * train_split)
test_size = int(total_samples * test_split)
# Split the dataset
dataset_train = dataset_full.select(range(train_size))
dataset_test = dataset_full.select(range(train_size, train_size + test_size))
dataset_validation = dataset_full.select(range(train_size + test_size, total_samples))
return dataset_train, dataset_validation, dataset_test
The latter training on the custom splited data (60-20-20) indeed showed improved accuracy and lower validation loss compared to the original subset splits:
| Split | Training loss | Validation loss | Accuracy |
|---|---|---|---|
| Original | 0.0724 | 0.3405 | 0.9174 |
| 60-20-20 | 0.0847 | 0.2441 | 0.9306 |
Model And Training Configuration
The BERT model ‘bert-base-uncased’ was loaded via the transformers library. According to BERT original paper Devlin et al. [1], when finetuning the BERT model, it was giving better results when model dropout was set to 0.1. (which is the default in the pre-trained bert base model being used here).
Additionally, the original paper refers to the parameters used for fine-tuning of pretrained model which I used here. The model was set up to train with batch size 32 for 3 epochs over the data. I selected the learning rate 2e-5 as the best performing from learning rate suggeted by original BERT paper (5e-5, 4e-5, 3e-5, and 2e-5).
The Trainer API was used to orchestrate the training. It enabled an easy and straightforward way to train the model by providing functions for computing loss and handling data. The progress was monitored with logging, and checkpoints were saved periodically by epoch. In the end the best perfoming model was uploaded into Hugging Face model hub.
training_args = TrainingArguments(
output_dir="bert-finetuned-sentiment",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
Fine-tuning results
Below are training results of the two fine-tuning tasks I ran. The first one is using the original BERT base as pre-trained model. The second-one then fine-tunes on the model from previous task.
Fine-tuning original BERT base with IMDB dataset:
| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 1 | 0.2788 | 0.1889 | 0.9278 |
| 2 | 0.1360 | 0.2246 | 0.9242 |
| 3 | 0.0847 | 0.2441 | 0.9306 |
Additional fine-tuning with GLUE dataset:
| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 1 | 0.171500 | 0.246300 | 0.910550 |
| 2 | 0.111400 | 0.323884 | 0.903670 |
| 3 | 0.075500 | 0.357894 | 0.912844 |
Evaluation
After training, I evaluated the model on a held-out test set from IMDB dataset, and Rotten Tomatoes dataset. The Rotten Tomatoes is dataset containing movie reviews, which is the same kind of data on which the model was trained, therefore the model should perform well on this dataset.
| Test set | Fine-tuned IMDB | Fine-tuned IMDB + GLUE SST2 |
|---|---|---|
| IMDb | 0.9257 | 0.9092 |
| Rotten Tomatoes | 0.822702 | 0.880863 |
IMDb Test Set:
- Fine-tuned on IMDb: Achieves an accuracy of 0.9257.
- Fine-tuned on IMDb + GLUE SST2: Achieves a slightly lower accuracy of 0.9092.
The model fine-tuned solely on IMDb data performs better on the IMDb test set. This indicates that the model is well-tailored to the specific domain and data distribution of IMDb reviews. When additional fine-tuning is done using GLUE SST2, the performance slightly drops, suggesting that the additional dataset introduces variability that might not align perfectly with the IMDb data.
Rotten Tomatoes Test Set:
- Fine-tuned on IMDb: Achieves an accuracy of 0.822702.
- Fine-tuned on IMDb + GLUE SST2: Achieves a higher accuracy of 0.880863.
The model fine-tuned on both IMDb and GLUE SST2 datasets performs significantly better on the Rotten Tomatoes test set. This suggests that the additional dataset (GLUE SST2) provides a broader range of sentiment expressions and contexts, which helps the model generalize better to different types of movie reviews found on Rotten Tomatoes.
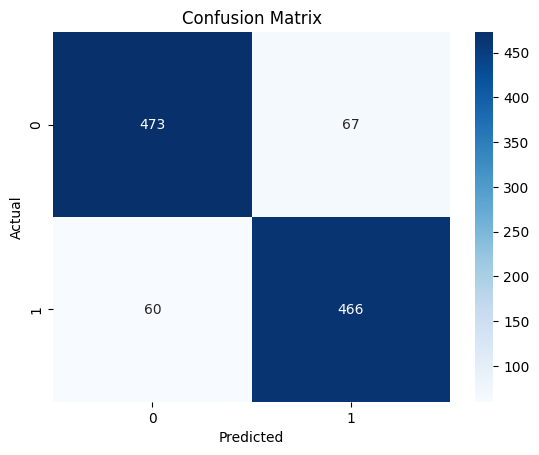
Key Insights
-
Overfitting to Specific Domains: The model fine-tuned exclusively on IMDb performs exceptionally well on the IMDb test set, indicating it may be overfitting to the specific characteristics of IMDb reviews.
-
Generalization Across Datasets: Incorporating the GLUE SST2 dataset helps the model generalize better, improving performance on a different dataset like Rotten Tomatoes. This suggests that a more diverse training set can enhance the model’s ability to handle varied data distributions.
Conclusion
These results highlight the trade-off between specialization and generalization in model training. Fine-tuning on a single dataset can yield high performance for that specific data but may limit the model’s versatility. Conversely, incorporating diverse datasets can improve the model’s robustness and adaptability to different data sources, which is crucial for real-world applications like fake news detection.
Model Deployment on Hugging Face Model Hub and Spaces
After training, I uploaded the model to the Hugging Face Model Hub, making it publicly accessible for others to explore and use. The Model Hub provides tools to organize, document, and version models, making them easier to share.
To demonstrate the model’s capabilities interactively, I built a web application using Gradio. This tool allows developers to create web-based UIs for machine learning models. The Gradio app was then hosted on Hugging Face Spaces, providing a seamless way to deploy and share it.
The Demo
Performance Benchmarks
For comparing performance of the models against baseline benchmarks I chose two models from Hugging face - DistilBERT base uncased finetuned SST-2 and SiEBERT - English-Language Sentiment Classification.
| Model | IMDB | Rotten Tomatoes |
|---|---|---|
| Fine-tuned IMDB | 0.9257 | 0.8227 |
| Fine-tuned IMDB + GLUE SST2 | 0.9092 | 0.8809 |
| DistilBERT SST-2 | 0.8868 | 0.8968 |
| Roberta Large English | 0.9497 | 0.9203 |
Conclusion
This project illustrates the power and convenience of the Hugging Face ecosystem for developing and deploying advanced NLP models. By fine-tuning BERT on the datasets and leveraging the Hugging Face Trainer API, Model Hub, and Spaces, I was able to create an effective sentiment analysis solution that is easily accessible to the community. Whether you’re looking to develop your own models or leverage existing ones, Hugging Face provides a rich set of tools that make the process smooth and efficient.
References
[1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding